The great esteemed Harper Reed’s Beard and his attached person wrote an excellent blog recently on LLM code generation and his techniques and approaches to building software with AI. I found a lot of similarities between what Harper does and what I’ve been using, so I wanted to write a quick “+1” to capture the similarities and differences and overall, highlight a few more techniques and technologies that folks can use to make the best software with the help of our AI friends. Let’s dive in!
If you want to skip all of this and watch a super quick video on the same flow, check it out below:
One key difference in my approach is that I’m really biased towards Google technologies. I could write a whole series of blogs on that specific topic, but suffice it to say that I’m still using Google technologies after ~1.5 decades in the Google orbit for good reasons. As Doug Cutting (co-creator of Hadoop) said, “Google is living a few years in the future and sending the rest of us messages.”
Planning with AI in IDX: Streamlining the development process
I like to start with a plan. In my experience as a developer, I find that I sometimes over-index on building. I get started, build a prototype, and then completely rethink my approach. That could be different platforms, underlying technologies, libraries, or system/software architectures. LLMs are hugely helpful in this stage, as I have a virtual peer programmer to toss ideas around with before I get myself buried in too much tech debt.
Similar to Harper, I start by prompting my LLM to ask me questions that can be used to help me think through my design and what I want to build. Unlike many approaches to this, which are somewhat disjointed, I like the no-context-switching option of doing all of this work in my IDE, and to accomplish that, I use Google’s IDX.
Contextual awareness and interactive planning: The Q&A process with Google Gemini
Once there, I’ll explain what I’m trying to do and ask Gemini to ask questions. The nice thing about having all of this in my IDE is that the LLM knows what I do and don’t have access to. For example, by connecting IDX to my Google Cloud project, it knows that I don’t just need any data warehouse, but rather can specifically use BigQuery. This comes in handy later when the same LLM can use all of that context to give me product-specific commands and code.
This seems like a good time to mention that I enjoy using IDX as my IDE for multiple reasons. Firstly, its nice being able to access my IDE from any device and not worry about where I want to work. It’s just a web app, after all. Secondly, the IDX and GCP integrations are numerous. Deploying something to Cloud Run requires a few clicks or a single command, inclusive of authentication. This makes things really simple and quick to deploy which I’ve found to be extremely important in the “build first, ask questions later” approach required for designing AI applications that leverage the latest state of the art. On top of all of the Gemini LLM magic we’re talking about here, there are also the “old school” (in that these are > 6 months old — an eternity in AI-land) code assistant features like code completion, code explanation, and code optimization. I’m not spending too much time on those here, but that may need to be a future blog post.
Back to the Gemini assistant in IDX, the Q & A often looks something like this:
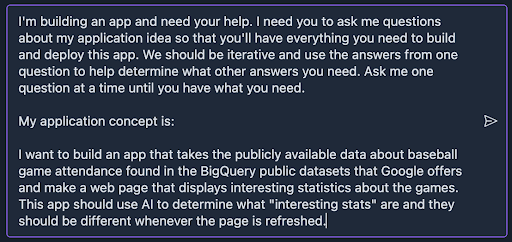
We then go through this type of back and forth. It’s worth noting that these questions can be technical but aren’t always. Gemini asks me about features and helps brainstorm the product itself before going into the technical design.
We also get detailed explanations for any recommendations, along with alternatives and their pros and cons.

Finally, I get a breakdown of our plan and get to make tweaks if I’d like to:
Project Plan: Baseball Attendance Statistics Web App
Goal: Create a simple web application that displays “interesting” statistics about baseball game attendance, derived from BigQuery public datasets using AI. The statistics will change each time the page is refreshed.
Technology Stack:
Backend: Python
Web Framework: Flask (microframework)
Data Source: Google BigQuery public datasets (specific dataset to be determined)
AI: Python AI libraries (to be determined)
Phase 1: Data Acquisition and Research (Me)
BigQuery Dataset Research: I will research the BigQuery public datasets to identify the most suitable one for baseball attendance data, ensuring it includes information about game dates, teams, and attendance figures. I will also determine how frequently it is updated.
Data Exploration: I will explore the chosen dataset to understand its structure and the available fields.
Data Extraction: I will start writing the code to extract the data we need from BigQuery using a Python script.
Phase 2: AI Analysis and Logic (Me)
“Interesting Statistic” Definition: We’ve agreed that “interesting” will encompass comparative, trend-based, and rare events in the data.
AI Logic Development: I will develop the core logic that analyzes the extracted data to identify and generate “interesting” statistics. This may involve:
– Comparing attendance figures between teams.
– Analyzing attendance trends over time (e.g., day vs. night games).
– Identifying rare events (e.g., infrequent matchups).
AI Libraries: I’ll research and select appropriate Python AI libraries to help with the analysis.
Dynamic Statistics: I will make sure that the code will ensure that the statistics generated are different on each page refresh.
Phase 3: Web Application Development (Me)
Flask Setup: I will set up the Flask web application framework.
API Endpoint: I will create an API endpoint that will run the AI code and return the interesting statistics to the web page.
HTML/CSS: I will create a simple HTML page for the user interface and style it with CSS.
JavaScript: I will use javascript to make the data load on the page, and to make the page refresh.
Phase 4: Integration and Testing (Me)
Integration: I will integrate the data extraction, AI logic, and Flask application.
Testing: I will thoroughly test the application to ensure it’s correctly pulling the data, generating interesting statistics, and displaying them properly on the web page.
Phase 5: Deployment (Future Step)
Deployment: Once the app is built we can discuss options for deploying the application.
Key Considerations:
Simplicity: We’re prioritizing a clean and simple UI.
Dynamic Statistics: The AI-generated statistics will be different on each page refresh.
Python/Flask: We’ve chosen Python and Flask for their strengths in data science and web development, respectively.
Next Steps:
If you approve of this plan, I will immediately start working on Phase 1: Data Acquisition and Research
Do you have any questions or feedback on this plan?

AI-driven development: Iterative code creation and refinement
It’s worth calling out that I’m specifically not moving from model to model to prevent context switching (both human and AI), but the trade-offs are few. For example, I don’t feel that I’m missing out by not using a dedicated reasoning model like Gemini 2.0 Flash Thinking because the Gemini model in IDX does the reasoning and is iterative in its “thought process” prior to answering.

The Gemini agent then goes through and runs commands, reads their outputs, and uses those outputs to determine the next step. The same applies to actually creating code; code is written, considered, tweaked, and then re-written without my intervention. At every step, I have the ability to see what specific changes are being made and make manual edits if I’d like.
Here’s an example of changing the frontend:


I just click “update file” and away we go!

Not bad!
Prototype-first approach: Balancing automation and expertise
Now I know this is missing some core development artifacts like tests (UAT, integration testing, functional testing), code review, etc, but like I said at the start of this post, I find that in today’s AI-first world, it’s best to prototype right now.
What I’ve just described gets me to “good enough.” I can prove my concept, see if things work, think through the frontend, the software architecture, and even the systems architecture, so I’m ready for the next step. In my experience, that next step often still involves clunky old Homo sapiens.
When I tell colleagues that I love using AI for code generation but still like to have human beings involved, I often hear a snarky remark along the lines of “ha! I knew this AI stuff was too good to be true!” and I want to be crystal clear that isn’t the case. With enough iterations and prompt engineering, I can eventually get the Gemini agent in IDX to do everything from soup to nuts, including HA deployment to GCP, without typing a single line of code or command. But doing that defeats the purpose: I want my AI overlords to make me more efficient, not spend extra time learning how to coax them into doing my bidding.
Real-world efficiency: Offloading tedious tasks to AI
Therefore, what I find works the best in the real world is letting the Gemini agent build my prototype, letting the agent deploy it to GCP, and then basically just offloading the tasks that are time-consuming for a human to the AI.
An example of this is: I tell the agent what to build, as we have here, but I know that I also want user metrics written to a database. I am opinionated and want to use BigQuery. So, I simply tell Gemini to write a function that logs every time a user hits the page and the output to a BQ database. I know that I need to create that database first, so I explicitly tell the agent to build it. I could probably coax Gemini into asking me if I want to use BigQuery, the name of the DB, etc., but in this case, I save the most time by being explicit.
What this means, at the end of the day, is that I can build an application in under an hour. Whereas in the past I might have gotten stuck remembering how exactly I need to set up Flask routing or what React code changes the mouse-over behavior of a button, I can just tell Gemini to do the thing I want. I think at one point I told it to make the frontend “more baseball” and it just did things.
What I’m not offloading are the parts of development that I enjoy, am good at, and do not take much time: the features I know I want, the system architecture I know works best, and the tools I’ve used to solve similar problems.
Expanding your AI development journey: Resources and expert support
Lastly, I’ll point curious minds to Harper’s original post which goes into much greater detail across many more technologies than I’ve covered here. He talks about the full process of going from idea to deployment with almost no hacking away at a keyboard and includes the core things that you’ll need post–prototype like tests, git integration, etc.
Please don’t hesitate to reach out and share your thoughts! I want to hear the hallucinations, the failures, the successes, and the surprises!
If you’re looking to accelerate your AI-driven development journey, SADA’s team of Google Cloud experts can help you navigate the complexities of LLMs, AI agents, and cloud infrastructure. We can assist with everything from strategic planning and implementation to optimization and ongoing support, ensuring you leverage the full potential of these technologies. Contact us today to learn how SADA can empower your software development in the age of AI.
