The Applied ML Summit was a part of the digital Google Cloud Summit series and covered one of the most rapidly changing areas in business today, and also one dear to my heart, machine learning (ML). This is an area that is evolving at an exponential pace and every day brings new innovations and technology, like Google’s new AI platform Vertex AI (which was shown off in several demonstrations and breakout sessions). The summit also explored other important topics across a multitude of areas, including how to prepare the next generation of data scientists, how to manage your models at scale, and how to properly develop an ML project. Featuring keynote speakers as well as demonstrations and sessions in between, the format gave high-level insight from innovators in the field while also enabling viewers to explore particular topics in depth.
Keynote

The summit started out with a keynote featuring Tony Jebara, Head of Machine Learning & VP of Engineering at Spotify. Jebara delved into how Spotify currently uses ML and how they plan to in the future. Key in Jebara’s speech was how ML is at the heart of everything Spotify does. For example, ML has been central in their continuing efforts to branch out into all audio formats, such as Spotify’s push into podcasts, and optimizing their audio content for every creator and listener. As Jebara stated, ML is at its best when its content is truly personalized and optimized for long-term enjoyment rather than short-term clicks.

Next, Jebara covered a future goal for Spotify, and one that I believe that every business should aspire to: moving from a fleet of transactional ML systems to an interconnected holistic system. The idea of all their ML systems working together is a powerful one. As an example, take the value that businesses currently get from independent systems and then imagine an integrated system! The entire speech is linked here, and it’s well worth a listen as Jebara delivered several keen insights into how ML should be used.
Breakout sessions and exploring Google’s new AI platform (Vertex AI)
The breakout sessions were split into MLOps Tutorials, Cutting-edge Innovation, and Advanced MLOps. Not having two other clones, I ended up bouncing around several different ML topics that I enjoy. Ultimately, I settled down into How Google does ML, Designing Inclusive ML Systems, and Kaggle Grandmasters ‘Ask Me Anything’: Putting Models Into Production. There was so much to cover in these sessions, but I’d like to highlight a couple of quotes and moments from them:
The Kaggle Grandmasters session had a number of great practical considerations when building ML systems. These Kaggle Grandmasters have often created hundreds of models and are deeply experienced in ML. I especially enjoyed this theoretical question from Jean-Francois Puget: say you had a model that could predict with 100% accuracy, what would you do with it? I think this question is critical—if you can’t answer it, then building a real-world model, which will have inaccuracies, is not going to help. Other good points from this session included elucidating the problem that the skills required to make an ML model are different from the skills needed for putting those models into production. This is something that many businesses face when starting with ML—they’ve hired a great team of data scientists and have gotten a model that is now working but need to put it into production. At this point, the skills change from being grounded in science and stats to a more engineering skill set which can take businesses off guard. The final tidbit from this group that I’d like to share was a famous quote from Edsger Dijkstra that he originally used for computer programming: “Premature optimization is the root of all evil.” In the ML context, the quote was used as an illustration of the enormous amount of time that can be consumed in optimizing a model. Sometimes, when a model works well enough, it works well enough!

One of the most important areas covered in several of the sessions (with a more in-depth discussion in Designing Inclusive ML Systems) was the topic of ethical responsibilities that should be inherent when building an ML model and putting it into production. This has been an area that all companies have had serious problems with in the past, so it was good to see that Google has put in some thoughtful practices across the company to address this issue. For those unaware of this growing area, Responsible AI is a set of principles that when used can help build ethical models that are transparent, fair, inclusive, and accountable. Google has taken this to heart, adopting better Responsible AI practices that start at the idea stage to ensure the desired product fits within the principles, and later going through two separate review processes, which are pan-Google and include technical and non-technical people (with some members having ethics backgrounds). These are all positive steps and welcome signs to ensure that ML doesn’t outpace the ethical considerations it creates.
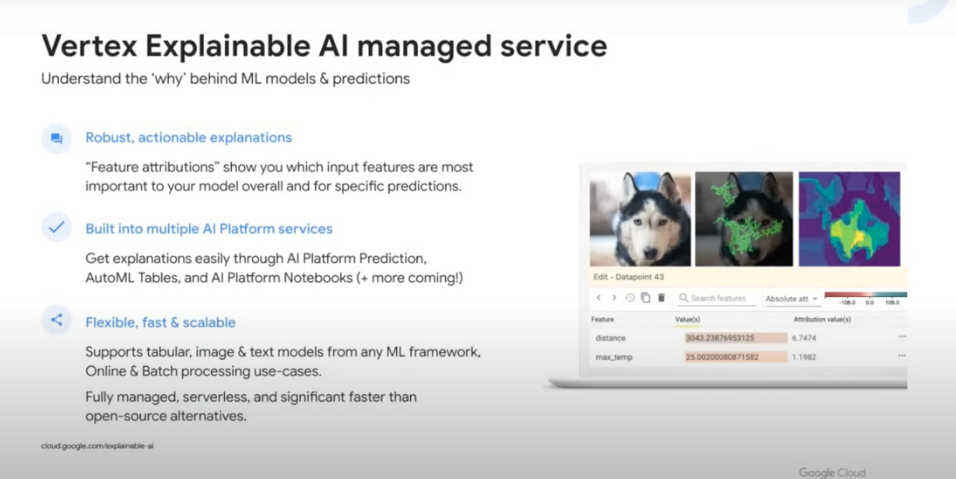
Many of the sessions showed off some of the new features found in Vertex AI, Google’s new AI system that is unifying the Google custom ML product offerings under a single platform. Some of these are upgraded versions of existing functionality, such as Vertex Pipelines and Vertex Model Monitoring. Some, like the Vertex Feature Store and Vertex Explainable AI, are new functionality that will be a great help to ML practitioners. This is a large step for Google that will allow for more insightful understanding of your data and features and more easily move models to a production MLOps system.
Closing keynote
The summit ended with a presentation by François Chollet about the next five years of deep learning. Here, he highlighted four important trends: ecosystems of reusable parts, increasing automation, larger-scale workflows, and real-world deployment. The first, reusable parts, would eliminate so much of the redundancy in how similar models are built on similar datasets that could be trained once, and reused forever. The second trend was increasing automation so that many tedious—but important!—operations such as hyperparameter tuning are achievable without manual intervention. The third trend François identified was the rise of faster and more efficient hardware solutions (such as TPUs) to make training faster and cloud-based to cut down on development time. Finally, he discussed real-world deployment with an increasing focus on resource-efficient models and deployments into mobile and embedded devices.
SADA is ready to help your business explore these innovative products, architectures, and best practices for taking your ML aspirations off the drawing board and into the clouds. Contact us to learn more.