At SADA, we’re working aggressively with generative AI, and we’re excited about the potential that this technology has to transform the way we work. Google recently made some big announcements in this space, but there’s still a lot of uncertainty about the competitive landscape and economics of generative AI.
Making decisions around generative AI pricing are part of a smart and comprehensive FinOps strategy. Let’s start by demystifying some of the main questions about generative AI pricing in particular.
Generative AI pricing: Google Vs. OpenAI
Google and OpenAI offer Generative AI models and services with different pricing structures. OpenAI, known for its GPT-3.5 and GPT-4 models, charges users based on the number of tokens processed, the model version, and the total compute time. Pricing tiers can vary based on usage volume and subscription type. Google, on the other hand, offers a suite of AI tools through Google Cloud Platform, including generative AI capabilities, and their pricing usually revolves around API calls, computation time, and the specific services used.
| Company | Model | Type | Price |
|---|---|---|---|
| OpenAI | GPT 4.0 8k context | Input | $0.03/1k tokens |
| Output | $0.06/1k tokens | ||
| GPT 4.0 32k context | Input | $0.06/1K tokens | |
| Output | $0.12/1K tokens | ||
| GPT-3.5 Turbo 4k context | Input | $0.0015/1K tokens | |
| Output | $0.002/1K tokens | ||
| GPT-3.5 Turbo 16k context | Input | $0.003/1K tokens | |
| Output | $0.004/1K tokens | ||
| PaLM 2 for Text | Input | $0.0005/1K characters | |
| Output | $0.0005/1K characters | ||
| PaLM 2 for Chat | Input | $0.0005/1K characters | |
| Output | $0.0005/1K characters |
1. Tokens vs. characters
Generative AI APIs are billed based on the volume of input they receive and the volume of output they generate. Different providers measure these volumes differently, with some measuring tokens and others measuring characters, but the concepts remain the same.
It’s important to understand the difference between a token and a character in order to properly compare pricing across providers. Per the OpenAI pricing documentation, a token is a unit of measure, representing approximately 4 characters. A character is a single letter, number, or symbol. For example, the word “hello” has five characters and may be slightly larger than one token.
Google’s generative AI service is priced based on the number of characters that are input and generated. OpenAI’s generative AI service is priced based on the number of tokens consumed and generated. This is important to understand when comparing costs between these platforms.
| Aspect | OpenAI | |
|---|---|---|
| Billing Metric | Characters | Tokens |
Definition of tokens and characters
Tokens: Within the realms of generative AI and linguistic analysis, a token is essentially a segment or piece of text the system processes. It might be a word, digit, or even a symbol. Take, for instance, the phrase “She adores ice-cream!” which is divided into four tokens: “She”, “adores”, “ice-cream”, and “!”.
Characters: Characters denote individual alphabets, digits, punctuation, and other signs composing text. In the domains of computer science and typography, a character encapsulates any letter, number, or sign computationally representable. For instance, the term “hello” is made up of five characters: h, e, l, l, o.
How different providers measure volumes: tokens vs. characters
Tokens-based measurement
- Typical use: Often preferred by advanced natural language processing (NLP) and generative AI systems. Tokens can represent a single word, punctuation mark, or even a number.
- Advantages: Provides a more consistent measure in terms of processing complexity. For instance, translating or processing a word usually requires more computational resources than a single character.
- Example: OpenAI’s GPT models typically use a token-based system. The token length can vary, and it’s not tied to individual characters or words in a strict sense. Tokens can represent subword units, whole words, or even longer sequences, depending on the text and language being processed.
Characters-based measurement
- Typical use: Common for services that focus on the raw number of characters processed, irrespective of the semantic or syntactic complexity.
- Advantages: Easier for users to understand and calculate. For tasks like transcription or simple text generation, character count might be more intuitive.
- Example: Google’s generative AI service is priced based on the number of characters that are input and generated.

2. Comparing text generation models: Google’s PaLM 2 text-bison-001 vs. OpenAI’s GPT-4
Following are some examples of pricing between two models: Google’s PaLM 2 text-bison-001 and OpenAI’s GPT-4. For the sake of simplicity, we’re focusing on the input costs only.
At Google, input and output costs are identical, whereas, at OpenAI, input costs are typically less expensive than outputs (though notably, ChatGPT has one price for both input and output; more on that later). We’ve also simplified the comparison by using a single measurement: characters. For OpenAI’s APIs, we’re using their documented reference of ~4 characters per token.
The table of price comparison:
| Service | Price (per 1k characters) | |
|---|---|---|
| Google text-bison-001 | Input | $0.0005 |
| Google text-bison-001 | Output | $0.0005 |
| Service | Price (per 1k tokens) | |
|---|---|---|
| GPT 4.0 8k context | Input | $0.03 |
| GPT 4.0 8k context | Output | $0.06 |
| GPT 4.0 32k context | Input | $0.06 |
| GPT 4.0 32k context | Output | $0.12 |
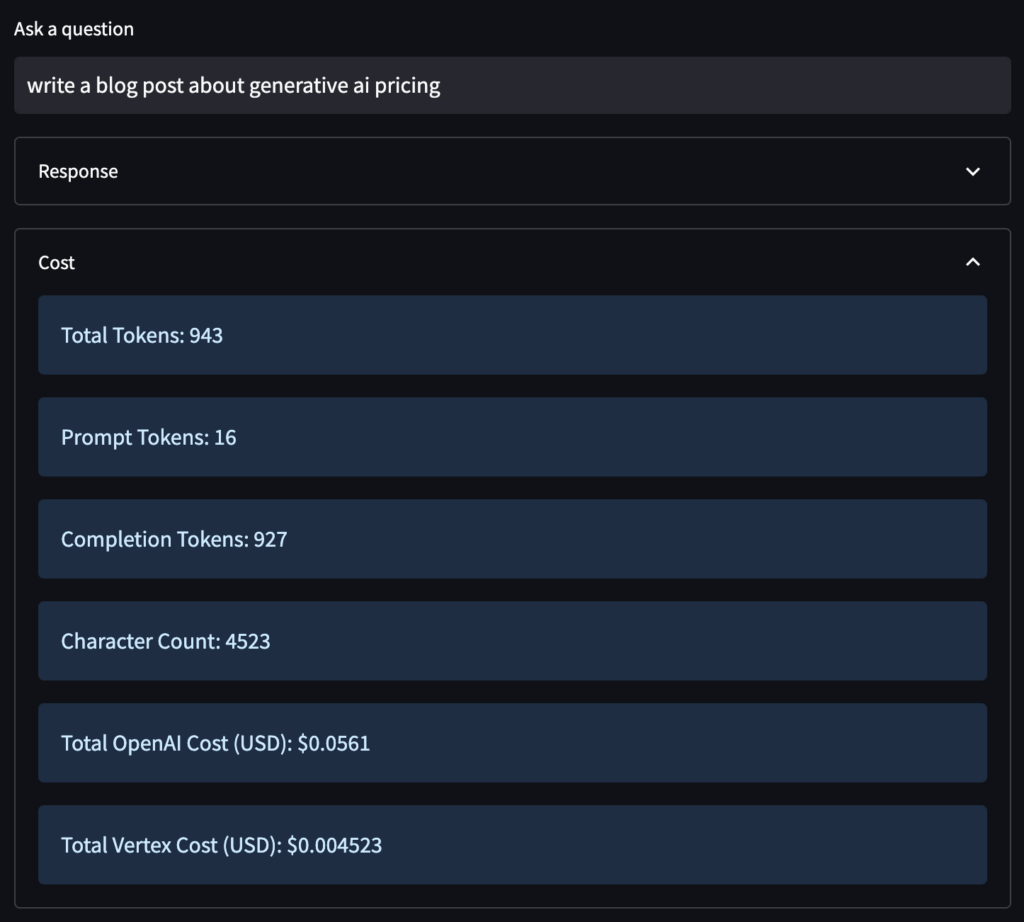
As you can see, Google’s generative AI service is priced significantly lower than OpenAI’s. In the case of text generation, Google’s “bison” version of the PaLM 2 model is ~7.5x less expensive than the OpenAI model in the same class, GPT-4. These orders of magnitude differences in pricing for the text can make a significant impact on teams that are doing everything from testing and development to viral-app production once Google is no longer 100% discounting the PaLM API.
Input costs as the primary comparison metric
When evaluating Google’s PaLM 2 text-bison-001 and OpenAI’s GPT-4 using input costs:
- Pricing models
Google’s PaLM 2-based models charge based on characters input, offering a transparent cost structure.
OpenAI’s GPT-4 uses a token-based pricing (approx. 4 characters = 1 token), adding a layer of conversion when comparing costs.
- Cost implications
Google’s models may offer cost-effective solutions on a per-character basis, which can be appealing for large-scale input tasks.
- Operational predictability
Clear input costs help businesses anticipate and budget for their AI expenses more efficiently.
- Broader considerations
Beyond just input costs, users should weigh the capabilities, output quality, and other features of each model to determine overall value.
In a nutshell, while input costs offer a direct comparison between Google’s PaLM 2-based models and OpenAI’s GPT-4, a comprehensive evaluation should also consider output quality and model capabilities.
Differences in pricing between input and output for each provider
The distinction between input and output pricing can impact a user’s cost, especially when running large-scale operations. Here’s a look at the general differences between input and output pricing for providers like Google and OpenAI:
- Google’s generative AI services
Input and output pricing: Historically, Google’s models, like the PaLM 2-based text-bison@001, often have identical costs for both input and output. This means that the charge per character (or other metric they use) remains consistent whether you’re sending data into the system or receiving generated text back.
- OpenAI’s services
Input and output pricing: OpenAI’s pricing strategy can vary between models. For some models, the input costs might be less expensive than the outputs, acknowledging that generating coherent and relevant text requires more computational resources than merely processing an input. However, certain models, like ChatGPT, have a unified pricing structure for both input and output.
Why it matters
Understanding these differences is crucial for businesses and developers. For instance, if a company is looking to do a lot of text generation (output) rather than just processing (input), they might find a service with a lower output cost more economical in the long run.
It also impacts how users structure their queries. With some models, users might be incentivized to use concise inputs to obtain more extended outputs, thereby maximizing the generated content within a certain budget.

3. Comparing chat models: Google’s PaLM 2 chat-bison-001 vs. OpenAI’s gpt-3.5 turbo
A slightly simpler example is to compare the two chat APIs: Google’s PaLM 2 chat-bison-001 and OpenAI’s gpt-3.5-turbo.
The table of price comparison:
| Service | Price (per 1k characters) | |
|---|---|---|
| Google chat-bison@001 | Input | $0.0005 |
| Google chat-bison@001 | Output | $0.0005 |
| Service | Price (per 1k tokens) | |
|---|---|---|
| GPT-3.5 Turbo 4k context | Input | $0.0015 |
| GPT-3.5 Turbo 4k context | Output | $0.002 |
| GPT-3.5 Turbo 16k context | Input | $0.003 |
| GPT-3.5 Turbo 16k context | Output | $0.004 |
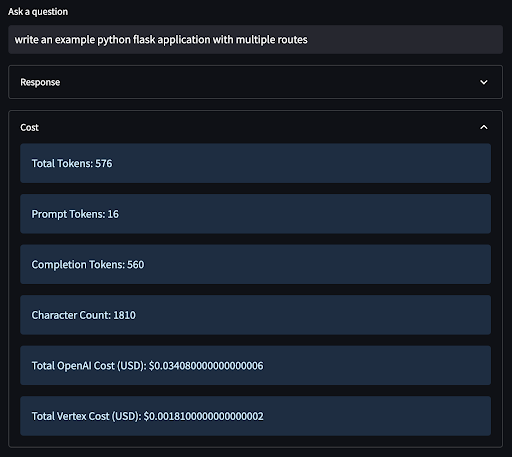
When it comes to the chat API, Google’s offering comes in at almost exactly the same cost. At face value, this may seem to indicate that the cost of adopting either API for chat would be identical, but that misses a key consideration-these APIs don’t exist in a vacuum. Rather, they are part of rich application environments consisting of data, application services, and-in the case of Google Cloud-the capacity to invoke a pipeline of multiple, purpose-built, additional AI APIs. These holistic application environments have been Google Cloud’s core competency for over a decade.
The misleading notion of similar pricing
While Google’s PaLM 2 chat-bison-001 and OpenAI’s gpt-3.5 turbo might have comparable pricing, this similarity can be misleading:
- Model foundations: Their underlying architectures and training differ, leading to potential variations in output quality.
- Integration ecosystem: Google’s model is embedded within its broader cloud services, offering potential synergy benefits.
- Output depth: Identical input costs don’t guarantee similar output quality or relevance.
- Operational factors: Scalability, uptime, and responsiveness can vary between the services, affecting real-world usability and costs.
- Hidden expenses: Integration and maintenance costs might differ, impacting the total cost of ownership.
In essence, the apparent similarity in pricing doesn’t necessarily reflect equivalence in value, performance, or overall cost.
Generative AI pricing is not just about per-character or per-token costs
Generative AI pricing extends beyond just per-character or per-token costs:
- Performance: Quality of AI outputs can vary, affecting overall value.
- Infrastructure: Costs can rise due to specific hardware or cloud requirements.
- Integration: Integrating the AI model into an existing system might incur expenses.
- Scalability: It’s vital to consider how costs change as usage increases.
- Support: Fees for technical support and updates can add up.
- Data costs: Charges for data transfer and storage in cloud solutions can be significant.
- Licensing: Commercial use might come with additional fees.
- Latency: Premium charges might apply for faster response times.
A holistic view of the ecosystem and integrated AI APIs is vital for optimizing AI’s value
When assessing and implementing AI solutions, it’s imperative to adopt a holistic perspective, rather than a narrow, tool-centric one. The larger ecosystem in which the AI operates-comprising application services, data pipelines, and interconnected AI APIs-plays a pivotal role in the overall success and efficiency of the solution. A standalone AI model, irrespective of its sophistication, can only offer so much. However, when harmoniously integrated with relevant application services and complemented by other specialized AI APIs, its potential magnifies. This synergy ensures seamless data flow, optimizes computational resources, and paves the way for multifaceted solutions. Thus, a comprehensive understanding and consideration of the broader ecosystem is essential to truly harness the power of AI.


The (very near) future of generative AI
It’s still too early to say who will win the battle for the generative AI market. However, the early signs suggest that Google is in a strong position. While not the first to market with a text or chat generative AI API, Google has been developing AI services for many years, ranging from sentiment analysis to generative text across search, Gmail, and Google Docs.
Generative AI has already begun to transform the way we work, and we’re thrilled to be at the forefront of this revolution alongside innovators who will define this space for years to come.
Learn more about SADA’s generative AI services and schedule a consultation on how to best incorporate generative AI into your business. We’ll be happy to hear from you.
Bonus: Generative AI glossary
Getting up to speed on all things related to generative AI? We’ve put together this handy glossary to stay current with all the new terminology.
Artificial Intelligence (AI): the capability of machines to carry out tasks typically linked to human intelligence.
Algorithm: A set of directions that a computer adheres to in order to solve a problem.
Attention: A mechanism within neural networks that enables them to concentrate on particular segments of an input sequence.
Autoencoder: A type of neural network that’s capable of learning to reconstruct its input.
Backpropagation: An algorithm that is tasked with training neural networks.
Batch size: The number of examples processed simultaneously during training.
Bias: AI bias refers to the inclination of AI algorithms to generate results that exhibit systematic differences for specific groups.
Bleu score: A measure of how alike two sequences of text are.
Boilerplate: A set of common phrases or words that are used in a particular context.
Brute force: A method of solving a problem by trying all possible solutions as quickly as possible
Character: An individual letter, number, or symbol.
Chunk: A group of tokens that are processed simultaneously by a neural network.
Codex: A collection of texts or documents.
Confusion matrix: A table that displays a model’s accuracy in classifying examples.
Convolution: A mathematical operation employed to extract features from an image.
Cost function: A measure of how effectively a model is performing.
Cross-entropy: A classification loss function that is used in classification tasks.
Data augmentation: A technique employed to expand the dataset size by artificially generating new examples.
Dataset: A collection of data that is used for training a model.
Decoder: A neural network that takes a sequence of tokens as an input and outputs a sequence of tokens.
Denoising autoencoder: An autoencoder that is trained on corrupted data for the purpose of reconstructing the original, uncorrupted data.
Discriminator: A neural network used to determine the difference between real and fake data.
Distributional semantics: A method of representing the meaning of words based on their contextual usage.
Embedding: A vector representation of a word or phrase.
Encoder: A neural network that accepts a sequence of tokens as an input and outputs a vector representation of the input.
Epoch: A single full pass through a dataset during the process of training.
Error: The variance between a model’s predictions and the actual values.
Embedding layer: A layer in a neural network that maps words or phrases to vectors.
Feature: A characteristic of an object or event.
Feature extraction: The process of identifying characteristics or features from data.
Feature vector: A representation of a feature in vector form.
Generative AI: A form of artificial intelligence that has the ability to create new content such as text, images, and music. It achieves this by learning from extensive datasets and subsequently using that knowledge to produce new content that resembles the data it has been trained on.
Gradient descent: An algorithm for finding the minimum of a function.
Gradient descent with momentum: A variant of gradient descent that uses a moving average of the gradients to improve convergence.
Gradient tape: A mechanism that records the gradients of a loss function with respect to the model’s parameters.
Hallucination: False, inaccurate, or misleading output from generative AI. This can happen when a program is trained on a dataset that contains incorrect or misleading information.
Hyperparameter: A parameter used to control the training of a model.
Image captioning: The task of generating a natural language description of an image.
Imitation learning: A form of machine learning in which an agent learns to behave by observing and imitating a human or another agent.
Inference: The process of using a model to make predictions on new or unseen data.
Instance: A single example in a dataset.
Loss function: A function used to quantify the error of a model
Machine learning: A field of computer science that gives computers the ability to learn without being explicitly programmed.
Manifold learning: A type of dimensionality reduction that maps data points to a lower-dimensional manifold.
Maximum likelihood: A method used to estimate the parameters of a model.
Mean squared error (MSE): A loss function that measures the squared difference between a model’s predictions and the actual values.
Mel-spectrogram: A representation of an audio signal that is used in speech recognition.
Model: A representation of a system in a mathematical form.
Neural network: A type of machine learning model inspired by the structure of the human brain.
Normalization: A process of transforming data so that it has a mean of 0 and a standard deviation of 1.
One-hot encoding: A way of representing categorical data as vectors.
Optimizer: A function used for updating the parameters of a model during training.
Overfitting: A problem that occurs when a model learns the training data too well and is then unable to generalize to new data.
Parameter: A value used to control how a model behaves.
Perplexity: A measure of how well a model is able to predict the next word in a sequence.
Phrase: A group of words that are used together to form a meaningful unit.
Prompt: A piece of text provided to a model to generate a response.
Recurrent neural network (RNN): A type of neural network that is able to process sequences of data.
Regularization: A technique that is used to prevent overfitting.
Reinforcement learning: A type of machine learning in which an agent learns to take actions in an environment to maximize a reward.
Representation: A way of encoding data so that it can be leveraged by a model.
Retrieval-based model: A type of generative model that generates text by pulling similar text from a dataset.
Sequence-to-sequence model: A type of neural network that has the ability to translate sequences of data from one form to another.
Skip-gram: A type of word embedding that is trained on a corpus of text.
Softmax: A function that is used to normalize a set of probabilities.
Speech recognition: The task of converting spoken language into text.
Stochastic gradient descent: A variant of gradient descent that uses a random subset of the data to update the model’s parameters.
Supervised learning: A type of machine learning in which the model is trained on labeled data.
Token: A single unit of text, such as a word, character, or punctuation mark.
Training set: A set of data used to train a model.
Transfer learning: A technique that is used to transfer knowledge from one task to another.
Unsupervised learning: A type of machine learning that doesn’t rely on predefined categories or specific target values, unlike supervised learning.
Value function: A function that represents the expected reward for taking a particular action in a particular state.
Word embedding: A word as represented by a vector.
Word2vec: A technique for learning word embeddings.
Zero-shot learning: A machine learning paradigm where a model is trained to recognize or understand objects, concepts, or classes it has never encountered during its training phase.
FAQ
The cost of generative AI varies based on several factors, including the platform chosen, the extent of usage, the specific application, and the required computational power. Additionally, costs can change depending on whether you’re accessing pre-trained models or training custom solutions. It’s crucial to consult with specific AI service providers to get a detailed and up-to-date pricing breakdown.
While some generative AI tools and platforms provide free tiers or limited demos for users to experiment with, comprehensive functionalities, high-performance computing, or commercial-scale applications typically come with associated costs or subscription fees.
The cost of AI varies significantly based on factors such as its type, complexity, purpose, and the infrastructure needed. Prices can fluctuate from free for rudimentary tools and platforms to potentially millions of dollars for sophisticated enterprise-grade solutions. When considering the adoption of AI, it’s essential to identify the specific requirements and functionalities needed and then engage with relevant providers to obtain a more detailed cost estimate.
The cost of AI varies significantly based on factors such as its type, complexity, purpose, and the infrastructure needed. Prices can fluctuate from free for rudimentary tools and platforms to potentially millions of dollars for sophisticated enterprise-grade solutions. When considering the adoption of AI, it’s essential to identify the specific requirements and functionalities needed and then engage with relevant providers to obtain a more detailed cost estimate.
The pricing strategy for AI depends on factors like development costs, market demand, competition, and value provided. Common models include subscription fees, pay-per-use, or tiered pricing based on features or usage limits.
